Kyber 和 Aigis-enc的不同之处
0 参数集的不同

1 Parse : B ∗ → Rq均匀随机采样Rq中的多项式
Parse 是将字节流解析成多项式表示的方法。
1.1 字节组合方式
-
Angis-enc:
- 每次从字节流中取两个字节 和 ,计算 。
- 然后,结果 会被对 取模并进行约简,最终如果 ,则该值赋给多项式的系数 。
-
Kyber:
- 同样每次取字节流中的三个字节 ,进行更加复杂的处理。
- 其中,计算分为两部分:
- 每个部分都进行对 的取模,并且分别判断是否满足条件 和 ,若满足则赋值给多项式的系数。
```verilog assign d1 = {4'd0, b_data[i_0 +:8]} + (({8'd0, b_data[i_1+:4]}) << 8); //-- d1 = b[i] + 256(b[i+1] mod + 16) assign d2 = ({4'd0, b_data[i_1+:8]} >> 4) + ({4'd0, b_data[i_2+:8]} << 4);//-- d2 = b[i+1]/16 + b[i+2]*16 ```verilog 对应 a_in变量的计算过程需要修改 其中A_generator中对应逻辑需要修改60和61行 assign d1 = {5'd0, b_data[i_0 +:8]} + (({8'd0, b_data[i_1+:8]}) << 8); //-- d1 = b[i] + 256(b[i+1] ) assign d2 = d1[12:0];//-- d2 = d1 mod+2^13
1.2 循环步长和字节流解析
- Angis-enc: 字节流每次增加 2 个字节(i 增加 2),也就是说每两字节构成一个系数,也就是13位构成一个系数。
- Kyber: 字节流每次增加 3 个字节(i 增加 3),也就是三个字节构成两个系数,12位构成一个系数。
```verilog 对应 assign i_0 变量的计算过程需要修改 其中A_generator中对应逻辑需要修改51行 assign i_0 = icnt << 3; //-- i_0 = icnt*8 0,24,48,72,...,744 assign i_1 = (icnt + 12'd1) << 3; //-- i_1 = (icnt+1)*8 8,32,56,80,...,752 assign i_2 = (icnt + 12'd2) << 3; 其中不需要i_2了 因此原因,其对应的142-155的逻辑也需要修改 case({d1_valid,d2_valid}) 2'b11: begin dout_pre = (dout_pre << 24) | (d1 << 12) | d2; dout_pre_num = dout_pre_num + 2; 将12改成13,24改成26 kyber情况所需要的i1数量必需大于256/2*3=384,但是其中生成的d1/d2有可能会大于3329,会有概率有些不有效,384*8/(3329/4096) ≈3780,如下面的图片可知,shake-128一次生成 1344,则取整后1344*3=4032>3780,所以i1=4032/8=504 而aigis-enc中i1数量必须大于256*2=512,但是其中生成的d1/d2有可能会大于7681,会有概率有些不有效,所以512*8/(7681/8192)≈4369,取整后1344*4=5376>4369,则此处i1=4369/8=672 所以a_in也需要增加,以及b,c的位数,对应源代码如下,和SHAKE_128.v文件的输出也要修改。 第 7 行 input [4031:0] a_in 第38~43行 genvar i1; generate for(i1=0; i1<504; i1=i1+1) begin assign b[4031-i1*8:4024-i1*8] = c[i1*8+7:i1*8]; end endgenerate
2 CBDη : → Rq 二项分布采样
算法逻辑一模一样
但是其中的η的参数取值不一样,并且对于这两个算法来说,如果在aigis-enc中使用地方不一样,参数取值不一样。根据需要的比特来决定。
代码修改点
为了适配 ram_wdata 从 8*12 变为 8*13,并将 12'd3329 变为 13'd7681,将η从2或者3修改为8或者4或者2主要涉及以下修改:
1. 修改 ram_wdata 的位宽
ram_wdata 原本是 96 位(8 * 12),现在要改为 104 位(8 * 13)。
output reg [103:0] ram_wdata, // 修改位宽从 96 改为 104
2. 修改溢出处理的模数
代码中 3329 需要替换为 7681:
ram_wdata[00+:13] = (a_temp1 < b_temp1) ? (13'd7681 + a_temp1 - b_temp1) : (a_temp1 - b_temp1);
ram_wdata[13+:13] = (a_temp2 < b_temp2) ? (13'd7681 + a_temp2 - b_temp2) : (a_temp2 - b_temp2);
ram_wdata[26+:13] = (a_temp5 < b_temp5) ? (13'd7681 + a_temp5 - b_temp5) : (a_temp5 - b_temp5);
ram_wdata[39+:13] = (a_temp6 < b_temp6) ? (13'd7681 + a_temp6 - b_temp6) : (a_temp6 - b_temp6);
ram_wdata[52+:13] = (a_temp3 < b_temp3) ? (13'd7681 + a_temp3 - b_temp3) : (a_temp3 - b_temp3);
ram_wdata[65+:13] = (a_temp4 < b_temp4) ? (13'd7681 + a_temp4 - b_temp4) : (a_temp4 - b_temp4);
ram_wdata[78+:13] = (a_temp7 < b_temp7) ? (13'd7681 + a_temp7 - b_temp7) : (a_temp7 - b_temp7);
ram_wdata[91+:13] = (a_temp8 < b_temp8) ? (13'd7681 + a_temp8 - b_temp8) : (a_temp8 - b_temp8);
- 这里将
12-bit计算改为13-bit计算。 +:12改为+:13以匹配新的数据宽度。
3. 修改 ram_wdata 的默认值
在 STATE0 和 STATE2 复位时,ram_wdata 需要调整:
ram_wdata = 104'd0; // 96'd0 改为 104'd0
4. 修改 a_temp 和 b_temp 的位宽
因为 ram_wdata 变为 13-bit 计算,a_temp 和 b_temp 需要从 12-bit 扩展到 13-bit:
wire [12:0] a_temp1, b_temp1, a_temp2, b_temp2, a_temp3, b_temp3;
wire [12:0] a_temp4, b_temp4, a_temp5, b_temp5, a_temp6, b_temp6;
wire [12:0] a_temp7, b_temp7, a_temp8, b_temp8;
- 这里
wire的位宽由12-bit扩展为13-bit。
5. 关于 cbd_num 的修改
原来 cbd_num 是一个 2 位的信号,用于区分不同的 eta 值。现在我们需要修改其功能,使得 cbd_num 能支持三个不同的 eta 值(分别为 eta = 2, eta = 4, 和 eta = 8),因此我们对其赋值和索引的计算方式进行了修改。
修改前:
assign index_a = (cbd_num == 2'd1) ? (({3'd0, counter_i})<<2) + (({3'd0, counter_i})<<1) :
({3'd0, counter_i})<<2;
assign index_b = (cbd_num == 2'd1) ? (({3'd0, counter_i})<<2) + (({3'd0, counter_i})<<1) + 11'd3 : (({3'd0, counter_i})<<2) + 11'd2;
修改后:
assign index_a = (cbd_num == 2'd0) ? (({5'd0, counter_i})<<2) : // eta=2时:2*i*n1=2*i*2
(cbd_num == 2'd1) ? (({5'd0, counter_i})<<3) : // eta=4时:2*i*n2=2*i*4
({5'd0, counter_i})<<4; // eta=8时:2*i*n3=2*i*8
assign index_b = (cbd_num == 2'd0) ? (({5'd0, counter_i})<<2) + 15'd2: // eta=2时:2*i*n1=2*i*2+2
(cbd_num == 2'd1) ? (({5'd0, counter_i})<<3) + 15'd4: // eta=4时:2*i*n2=2*i*4+4
({5'd0, counter_i})<<4 + 15'd8; // eta=8时:2*i*n3=2*i*8+8
解释:
cbd_num == 2'd0对应eta = 2,此时索引计算为2*i*2。cbd_num == 2'd1对应eta = 4,此时索引计算为2*i*4。cbd_num == 2'd2对应eta = 8,此时索引计算为2*i*8。index_a为12位信号,counter_i为10位信号,则3'd0,修改为5'd0,防止溢出
6. 关于 cbd_in 输入比特流宽度的修改
原先,cbd_in 的宽度为 1536 位(即 256 * 3 / 4 * 8 = 1536),但由于输入比特流的长度需要满足可以被 8 整除的要求,同时考虑到 eta = 8 的情况,我们将其扩展为 4096 位。
修改前:
input [1536-1:0] cbd_in; // 输入比特流(用于CBD采样)
修改后:
input [4096-1:0] cbd_in; // 输入比特流(用于CBD采样)
解释:
- 根据新的要求,满足最大
eta为 8 的情况。计算得出256 * 8 / 4 * 8 = 4087,因此将输入数据长度扩展为 4096 位。
7. 关于 b_data 的重排修改
由于输入比特流长度的变化,b_data 的生成需要相应地调整。原本的 b_data 生成使用了 i 的最大值为 192(1536 / 8 = 192),现在需要将 i 的最大值修改为 511(4096 / 8 = 512),同时调整 b_data 的生成方式。
修改前:
generate
for (i=0; i<192; i=i+1) begin: gen_b_str
assign b_data[1535-i*8 : 1528-i*8] = cbd_in[i*8+7 : i*8];
end
endgenerate
修改后:
generate
for (i=0; i<512; i=i+1) begin: gen_b_str
assign b_data[4095-i*8 : 4087-i*8] = cbd_in[i*8+7 : i*8];
end
endgenerate
解释:
- 修改后的
b_data会处理新的输入数据长度4096位,i的范围调整为0到511(共 512 个数据块)。每个数据块的大小为 8 位,并依次从cbd_in中提取。
8. 关于 b_2 和 b_3 的修改
根据 eta 的不同值,我们需要调整 b_2 和 b_3 的赋值。对于不同的 eta,b_2 和 b_3 会从 b_data 中提取不同的部分。
eta = 8(cbd_num == 2'd2)时,b_data 的大小为 4095:0。
eta = 4(cbd_num == 2'd1)时,b_2 的大小为 4095:2048。
eta = 2(cbd_num == 2'd0)时,b_3 的大小为 4095:3072,并新增 b_3。
修改前:
assign b_2 = b_data[1535:512];
修改后:
assign b_2 = b_data[4095:2048] ; // eta=4时:b_data[4095:2048]
assign b_3 = b_data[4095:3072] ; // eta=2时:b_data[4095:3072]
解释:原本只有两个eta值,现在有3个,所以需要增加以一个b_3
因为eta=4时,2*256*4=2048,
则将原本的assign b_2 = b_data[1535:512]; 修改为assign b_2 = b_data[4095:2048];(因为4095-2048=2047)
因为eta=2时,2*256*2=1024,
所以再加一个assign b_3 = b_data[4095:3072](因为4095-3072=1023)
9. a_temp1 计算公式的修改
你要求修改 a_temp1 的计算公式,使得当 cbd_num 为不同值时,进行不同的加法操作。并且 11 位改为 12 位,修改后的代码逻辑如下:
原代码:
assign a_temp1 = (cbd_num == 2'd1) ? {11'd0, b_data[index_a]} + {11'd0, b_data[index_a+11'd1]} + {11'd0, b_data[index_a+11'd2]} :
{11'd0, b_2[index_a]} + {11'd0, b_2[index_a+11'd1]};
assign b_temp1 = (cbd_num == 2'd1) ? {11'd0, b_data[index_b]} + {11'd0, b_data[index_b+11'd1]} + {11'd0, b_data[index_b+11'd2]} :{11'd0, b_2[index_b]} + {11'd0, b_2[index_b+11'd1]};
修改后的代码:
assign a_temp1 = (cbd_num == 2'd0) ? {12'd0, b_3[index_a]} + {12'd0, b_3[index_a+12'd1]} : // cbd_num == 00: 使用 b_3 数据
(cbd_num == 2'd1) ? {12'd0, b_2[index_a]} + {12'd0, b_2[index_a+12'd1]} +
{12'd0, b_2[index_a+12'd2]} + {12'd0, b_2[index_a+12'd3]} : // cbd_num == 01: 使用 b_2数据
{12'd0, b_data[index_a]} + {12'd0, b_data[index_a+12'd1]} + {12'd0, b_data[index_a+12'd2]} +
{12'd0, b_data[index_a+12'd3]} + {12'd0, b_data[index_a+12'd4]} + {12'd0, b_data[index_a+12'd5]} +
{12'd0, b_data[index_a+12'd6]} + {12'd0, b_data[index_a+12'd7]}; // cbd_num == 11: 使用 b_data 数据,8项加法
修改解释:
cbd_num == 00时,使用b_3[index_a]和b_3[index_a+1]来计算a_temp1。cbd_num == 01时,使用b_2来计算a_temp1cbd_num == 11时,使用b_data[index_a]到b_data[index_a+7],共进行 8 项加法。
10. i 变化时 index 调整的修改
原逻辑:
- 当
i=0时,f0,index+,f1,index+ - 当
i=1时,f1,index+6*1,f1,index+4*1 - 当
i=64时,f64,index+6*64,f64,index+4*64 - 当
i=65时:f65,index+6*65;f65,index+4*65 - 当
i=128时:f128,index+6*128;f128,index+4*128 - 当
i=129时:f129,index+6*129;f129,index+4*129 - 当
i=192时:f192,index+6*192;f192,index+4*192 - 当
i=193时:f193,index+6*193;f193,index+4*193
修改后逻辑:
每行对应一个 i,后面跟着按 6*i 和 4*i 计算的 index。
- 当
i=0时,f0,index,f0,index,f0,index - 当
i=1时,f1,index+4*1,f1,index+8*1,index+16*1 - 当
i=64时,f64,index+4*64→256,f64,index+8*64→512,index+16*64→1024 - 当
i=65时:f65,index+4*65→260,f65,index+8*65→520,f65,index+16*65→1040 - 当
i=128时:f128,index+4*128→512,f128,index+8*128→1024,f128,index+16*128→2048 - 当
i=129时:f129,index+4*129→516,f129,index+8*129→1032,f129,index+16*129→2064 - 当
i=192时:f192,index+4*192→768,f192,index+8*192→1536,f192,index+16*192→3072 - 当
i=193时:f193,index+4*193→772,f193,index+8*193→1544,f193,index+16*193→3088
原来的代码:
//-- when i=1 => f1,index+6*1; f1,index+4*1
assign a_temp2 = (cbd_num == 2'd1) ? {11'd0, b_data[index_a+11'd6]} + {11'd0, b_data[index_a+11'd7]} + {11'd0, b_data[index_a+11'd8]} :
{11'd0, b_2[index_a+11'd4]} + {11'd0, b_2[index_a+11'd5]};
assign b_temp2 = (cbd_num == 2'd1) ? {11'd0, b_data[index_b+11'd6]} + {11'd0, b_data[index_b+11'd7]} + {11'd0, b_data[index_b+11'd8]} :
{11'd0, b_2[index_b+11'd4]} + {11'd0, b_2[index_b+11'd5]};
修改后的代码:
// a_temp2 and b_temp2 for i = 1//-- when i=1 => `f0,index+4*1`,`f1,index+8*1`,`index+16*1`
// a_temp2 and b_temp2 for i = 1
assign a_temp2 = (cbd_num == 2'd0) ? {12'd0, b_3[index_a+12'd4]} + {12'd0, b_3[index_a+12'd5]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_a+12'd8]} + {12'd0, b_2[index_a+12'd9]} + {12'd0, b_2[index_a+12'd10]} + {12'd0, b_2[index_a+12'd11]} :
{12'd0, b_data[index_a+12'd16]} + {12'd0, b_data[index_a+12'd17]} + {12'd0, b_data[index_a+12'd18]} + {12'd0, b_data[index_a+12'd19]} +
{12'd0, b_data[index_a+12'd20]} + {12'd0, b_data[index_a+12'd21]} + {12'd0, b_data[index_a+12'd22]} + {12'd0, b_data[index_a+12'd23]};
assign b_temp2 = (cbd_num == 2'd0) ? {12'd0, b_3[index_b+12'd4]} + {12'd0, b_3[index_b+12'd5]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_b+12'd8]} + {12'd0, b_2[index_b+12'd9]} + {12'd0, b_2[index_b+12'd10]} + {12'd0, b_2[index_b+12'd11]} :
{12'd0, b_data[index_b+12'd16]} + {12'd0, b_data[index_b+12'd17]} + {12'd0, b_data[index_b+12'd18]} + {12'd0, b_data[index_b+12'd19]} +
{12'd0, b_data[index_b+12'd20]} + {12'd0, b_data[index_b+12'd21]} + {12'd0, b_data[index_b+12'd22]} + {12'd0, b_data[index_b+12'd23]};
// a_temp3 and b_temp3 for i = 64//- 当 `i=64` 时,`f64,index+4*64→256`,`f64,index+8*64→512`,`index+16*64→1024`
assign a_temp3 = (cbd_num == 2'd0) ? {12'd0, b_3[index_a+12'd256]} + {12'd0, b_3[index_a+12'd257]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_a+12'd512]} + {12'd0, b_2[index_a+12'd513]} + {12'd0, b_2[index_a+12'd514]} + {12'd0, b_2[index_a+12'd515]} :
{12'd0, b_data[index_a+12'd1024]} + {12'd0, b_data[index_a+12'd1025]} + {12'd0, b_data[index_a+12'd1026]} + {12'd0, b_data[index_a+12'd1027]} +
{12'd0, b_data[index_a+12'd1028]} + {12'd0, b_data[index_a+12'd1029]} + {12'd0, b_data[index_a+12'd1030]} + {12'd0, b_data[index_a+12'd1031]};
assign b_temp3 = (cbd_num == 2'd0) ? {12'd0, b_3[index_b+12'd256]} + {12'd0, b_3[index_b+12'd257]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_b+12'd512]} + {12'd0, b_2[index_b+12'd513]} + {12'd0, b_2[index_b+12'd514]} + {12'd0, b_2[index_b+12'd515]} :
{12'd0, b_data[index_b+12'd1024]} + {12'd0, b_data[index_b+12'd1025]} + {12'd0, b_data[index_b+12'd1026]} + {12'd0, b_data[index_b+12'd1027]} +
{12'd0, b_data[index_b+12'd1028]} + {12'd0, b_data[index_b+12'd1029]} + {12'd0, b_data[index_b+12'd1030]} + {12'd0, b_data[index_b+12'd1031]};
//当 `i=65` 时: `f65,index+4*65→260,f65,index+8*65→520,f65,index+16*65→1040`
assign a_temp4 = (cbd_num == 2'd0) ? {12'd0, b_3[index_a+12'd260]} + {12'd0, b_3[index_a+12'd261]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_a+12'd520]} + {12'd0, b_2[index_a+12'd521]} + {12'd0, b_2[index_a+12'd522]} + {12'd0, b_2[index_a+12'd523]} :
{12'd0, b_data[index_a+12'd1040]} + {12'd0, b_data[index_a+12'd1041]} + {12'd0, b_data[index_a+12'd1042]} + {12'd0, b_data[index_a+12'd1043]} +
{12'd0, b_data[index_a+12'd1044]} + {12'd0, b_data[index_a+12'd1045]} + {12'd0, b_data[index_a+12'd1046]} + {12'd0, b_data[index_a+12'd1047]};
assign b_temp4 = (cbd_num == 2'd0) ? {12'd0, b_3[index_b+12'd260]} + {12'd0, b_3[index_b+12'd261]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_b+12'd520]} + {12'd0, b_2[index_b+12'd521]} + {12'd0, b_2[index_b+12'd522]} + {12'd0, b_2[index_b+12'd523]} :
{12'd0, b_data[index_b+12'd1040]} + {12'd0, b_data[index_b+12'd1041]} + {12'd0, b_data[index_b+12'd1042]} + {12'd0, b_data[index_b+12'd1043]} +
{12'd0, b_data[index_b+12'd1044]} + {12'd0, b_data[index_b+12'd1045]} + {12'd0, b_data[index_b+12'd1046]} + {12'd0, b_data[index_b+12'd1047]};
//当 `i=128` 时: `f128,index+4*128→512,f128,index+8*128→1024,f128,index+16*128→2048`
assign a_temp5 = (cbd_num == 2'd0) ? {12'd0, b_3[index_a+12'd512]} + {12'd0, b_3[index_a+12'd513]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_a+12'd1024]} + {12'd0, b_2[index_a+12'd1025]} + {12'd0, b_2[index_a+12'd1026]} + {12'd0, b_2[index_a+12'd1027]} :
{12'd0, b_data[index_a+12'd2048]} + {12'd0, b_data[index_a+12'd2049]} + {12'd0, b_data[index_a+12'd2050]} + {12'd0, b_data[index_a+12'd2051]} +
{12'd0, b_data[index_a+12'd2052]} + {12'd0, b_data[index_a+12'd2053]} + {12'd0, b_data[index_a+12'd2054]} + {12'd0, b_data[index_a+12'd2055]};
assign b_temp5 = (cbd_num == 2'd0) ? {12'd0, b_3[index_b+12'd512]} + {12'd0, b_3[index_b+12'd513]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_b+12'd1024]} + {12'd0, b_2[index_b+12'd1025]} + {12'd0, b_2[index_b+12'd1026]} + {12'd0, b_2[index_b+12'd1027]} :
{12'd0, b_data[index_b+12'd2048]} + {12'd0, b_data[index_b+12'd2049]} + {12'd0, b_data[index_b+12'd2050]} + {12'd0, b_data[index_b+12'd2051]} +
{12'd0, b_data[index_b+12'd2052]} + {12'd0, b_data[index_b+12'd2053]} + {12'd0, b_data[index_b+12'd2054]} + {12'd0, b_data[index_b+12'd2055]};
//当 `i=129` 时:`f129,index+4*129→516,f129,index+8*129→1032,f129,index+16*129→2064`
assign a_temp6 = (cbd_num == 2'd0) ? {12'd0, b_3[index_a+12'd516]} + {12'd0, b_3[index_a+12'd517]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_a+12'd1032]} + {12'd0, b_2[index_a+12'd1033]} + {12'd0, b_2[index_a+12'd1034]} + {12'd0, b_2[index_a+12'd1035]} :
{12'd0, b_data[index_a+12'd2064]} + {12'd0, b_data[index_a+12'd2065]} + {12'd0, b_data[index_a+12'd2066]} + {12'd0, b_data[index_a+12'd2067]} :
{12'd0, b_data[index_a+12'd2068]} + {12'd0, b_data[index_a+12'd2069]} + {12'd0, b_data[index_a+12'd2070]} + {12'd0, b_data[index_a+12'd2071]} ;
assign b_temp6 = (cbd_num == 2'd0) ? {12'd0, b_3[index_b+12'd516]} + {12'd0, b_3[index_b+12'd517]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_b+12'd1032]} + {12'd0, b_2[index_b+12'd1033]} + {12'd0, b_2[index_b+12'd1034]} + {12'd0, b_2[index_b+12'd1035]} :
{12'd0, b_data[index_b+12'd2064]} + {12'd0, b_data[index_b+12'd2065]} + {12'd0, b_data[index_b+12'd2066]} + {12'd0, b_data[index_b+12'd2067]} :
{12'd0, b_data[index_b+12'd2068]} + {12'd0, b_data[index_b+12'd2069]} + {12'd0, b_data[index_b+12'd2070]} + {12'd0, b_data[index_b+12'd2071]};
//当 `i=192` 时: `f192,index+4*192→768,f192,index+8*192→1536,f192,index+16*192→3072`
assign a_temp6 = (cbd_num == 2'd0) ? {12'd0, b_3[index_a+12'd768]} + {12'd0, b_3[index_a+12'd769]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_a+12'd1536]} + {12'd0, b_2[index_a+12'd1537]} + {12'd0, b_2[index_a+12'd1538]} + {12'd0, b_2[index_a+12'd1539]} :
{12'd0, b_data[index_a+12'd3072]} + {12'd0, b_data[index_a+12'd3073]} + {12'd0, b_data[index_a+12'd3074]} + {12'd0, b_data[index_a+12'd3075]} +
{12'd0, b_data[index_a+12'd3076]} + {12'd0, b_data[index_a+12'd3077]} + {12'd0, b_data[index_a+12'd3078]} + {12'd0, b_data[index_a+12'd3079]};
assign b_temp6 = (cbd_num == 2'd0) ? {12'd0, b_3[index_b+12'd768]} + {12'd0, b_3[index_b+12'd769]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_b+12'd1536]} + {12'd0, b_2[index_b+12'd1537]} + {12'd0, b_2[index_b+12'd1538]} + {12'd0, b_2[index_b+12'd1539]} :
{12'd0, b_data[index_b+12'd3072]} + {12'd0, b_data[index_b+12'd3073]} + {12'd0, b_data[index_b+12'd3074]} + {12'd0, b_data[index_b+12'd3075]} +
{12'd0, b_data[index_b+12'd3076]} + {12'd0, b_data[index_b+12'd3077]} + {12'd0, b_data[index_b+12'd3078]} + {12'd0, b_data[index_b+12'd3079]};
//当 `i=193` 时:`f193,index+4*193→772,f193,index+8*193→1544,f193,index+16*193→3088`
assign a_temp8 = (cbd_num == 2'd0) ? {12'd0, b_3[index_a+12'd772]} + {12'd0, b_3[index_a+12'd773]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_a+12'd1544]} + {12'd0, b_2[index_a+12'd1545]} + {12'd0, b_2[index_a+12'd1546]} + {12'd0, b_2[index_a+12'd1547]} :
{12'd0, b_data[index_a+12'd3088]} + {12'd0, b_data[index_a+12'd3089]} + {12'd0, b_data[index_a+12'd3090]} + {12'd0, b_data[index_a+12'd3091]} :
{12'd0, b_data[index_a+12'd3092]} + {12'd0, b_data[index_a+12'd3093]} + {12'd0, b_data[index_a+12'd3094]} + {12'd0, b_data[index_a+12'd3095]};
assign b_temp8 = (cbd_num == 2'd0) ? {12'd0, b_3[index_b+12'd772]} + {12'd0, b_3[index_b+12'd773]} :
(cbd_num == 2'd1) ? {12'd0, b_2[index_b+12'd1544]} + {12'd0, b_2[index_b+12'd1545]} + {12'd0, b_2[index_b+12'd1546]} + {12'd0, b_2[index_b+12'd1547]} :
{12'd0, b_data[index_b+12'd3088]} + {12'd0, b_data[index_b+12'd3089]} + {12'd0, b_data[index_b+12'd3090]} + {12'd0, b_data[index_b+12'd3091]} :
{12'd0, b_data[index_b+12'd3092]} + {12'd0, b_data[index_b+12'd3093]} + {12'd0, b_data[index_b+12'd3094]} + {12'd0, b_data[index_b+12'd3095]};
修改解释:
- 当
i=1时,index依次增加4*1、8*1和16*1。 - 当
i=64时,index依次增加4*64、8*64和16*64。
这段代码的核心是通过计算index的不同eta(4、8、16)来满足不同的需求。
3 编码与解码
算法逻辑一模一样
只有其中的l的参数取值不一样,A并且对于这两个算法来说,如果在aigis-enc中使用地方不一样,参数取值不一样。根据需要的比特来决定。对应coder.v文件
1. 位数修改
- 所有 [6399:0]改成 [5375:0] 因为公钥输入,大小为 122562 + 256 变成 dt·k·n+n = 102256+256=5376
- 所有 [13055:0]改成 [12543:0] 因为私钥输入,大小为 122562 变成13kn=132256=6656//(13+10)2256+3*256=12544
- input [6143:0] c_in 改成 [5375:0] 因为密文输入,大小为 102562 + 4*256 变成 9⋅2⋅256+3⋅256=5376
- output [6143:0] sk_out
//-- store s at Key_gen, store m at Enc, store s/m at Dec
reg [6143:0] s_m_reg;
reg [6143:0] m_reg;
改成 [6655:0] 因为 122562 变成13 * 2*256=6656 - output [6143:0] code_out 改成[5375:0] 因为密文输出,大小为 10 * 256 * 2 + 4 * 256 变成 9⋅2⋅256+3⋅256=5376
- 所有 [95:0] 变成 [103:0] 因为从12 * 8变成13 * 8
- reg [6143:0] t_c_reg;// 存储 t(密钥生成时)或 t/c(加密时)或 c(解密时)
此处或许需要再加两个,
因为当t(密钥生成时),因为从96 * 64变成 8064=5120,位数为[5119:0];
当t/c(加密时),位数从80 * 64+32 * 32变成 72 * 64+24 * 32=5376,位数为[5375:0]
当 c(解密时),位数从9664变成104*64=6656,位数为[6655:0] - reg [5119:0] decode_u_reg;需要从 80 * 64变成 72 * 64 = 4608,即[4607:0]
reg [1023:0] decode_v_reg;需要从 32 * 32变成 24 * 32 = 768,即[765:0]
位数修改
- 所有
[6399:0]改成[5375:0]- 原因:公钥输入,大小由
12*256*2 + 256变为dt·k·n+n = 10*2*256+256=5376
- 原因:公钥输入,大小由
- 所有
[13055:0]改成[12543:0]- 原因:私钥输入,大小由
12*256*2变为13*k*n=13*2*256=6656,计算方式为(13+10)*2*256+3*256=12544
- 原因:私钥输入,大小由
input [6143:0] c_in改成[5375:0]- 原因:密文输入,大小由
10*256*2 + 4*256变为9⋅2⋅256+3⋅256=5376
- 原因:密文输入,大小由
- 输出
sk_out修改
- 修改内容:
output [6143:0] sk_out改为output [6655:0] sk_out
- 修改原因:
- 存储
s(密钥生成时)、m(加密时)或s/m(解密时)的位数由12 * 256 * 2变更为13 * 2 * 256 = 6656 - 代码调整:
//-- store s at Key_gen, store m at Enc, store s/m at Dec reg [6655:0] s_m_reg; reg [6655:0] m_reg;
- 存储
-
输出
code_out修改- 修改内容:
output [6143:0] code_out改为output [5375:0] code_out
- 修改原因:
- 密文输出的大小由
10 * 256 * 2 + 4 * 256变更为9 * 2 * 256 + 3 * 256 = 5376
- 密文输出的大小由
- 修改内容:
-
所有
[95:0]修改为[103:0]- 修改原因:
- 位数由
12 * 8 = 96变更为13 * 8 = 104
- 位数由
- 修改原因:
-
t_c_reg修改- 根据
t、t/c或c的不同用途,位数需要相应调整:- 密钥生成 (
t):- 位数由
96 * 64变更为80 * 64 = 5120 reg [5119:0] t_c_reg;
- 位数由
- 加密 (
t/c):- 位数由
80 * 64 + 32 * 32变更为72 * 64 + 24 * 32 = 5376 reg [5375:0] t_c_reg;
- 位数由
- 解密 (
c):- 位数由
96 * 64变更为104 * 64 = 6656 reg [6655:0] t_c_reg;
- 位数由
- 密钥生成 (
- 根据
-
decode_u_reg和decode_v_reg修改decode_u_reg:reg [5119:0] decode_u_reg;- 修改为
reg [4607:0] decode_u_reg; - 位数由
80 * 64 = 5120变更为72 * 64 = 4608
decode_v_reg:reg [1023:0] decode_v_reg;- 修改为
reg [765:0] decode_v_reg; - 位数由
32 * 32 = 1024变更为24 * 32 = 768
原来的代码
//-- register wires
reg [95:0] t_c_reg_t_in [63:0];
wire [95:0] t_c_reg_t [63:0];
reg [79:0] t_c_reg_u_in [63:0];
wire [79:0] t_c_reg_u [63:0];
reg [31:0] t_c_reg_v_in [31:0];
wire [31:0] t_c_reg_v [31:0];
//-- The data read from the RAM is placed here
reg [95:0] s_m_reg_s_in [63:0];
wire [95:0] s_m_reg_s [63:0];
reg [7:0] m_reg_in [31:0];
wire [7:0] s_m_reg_m [31:0];
修改的代码
//-- register wires
reg [103:0] t_c_reg_t_in [63:0];
wire [103:0] t_c_reg_t [63:0];
reg [71:0] t_c_reg_u_in [63:0];
wire [71:0] t_c_reg_u [63:0];
reg [23:0] t_c_reg_v_in [31:0];
wire [23:0] t_c_reg_v [31:0];
//-- The data read from the RAM is placed here
reg [103:0] s_m_reg_s_in [63:0];
wire [103:0] s_m_reg_s [63:0];
reg [7:0] m_reg_in [31:0];
wire [7:0] s_m_reg_m [31:0];
相应的,后续代码中位数对应修改即可,这里的修改原因,可以见后面参数修改部分
2.算法4中 KeyGen_Encode_sk参数修改
原来的代码:
KeyGen_Encode_sk: begin
//-- 512 coefficients require 64 addresses
for (i=0; i<64; i=i+1) begin
s_m_reg[i*96 +: 96] <= {s_m_reg_s_in[i][91:84], s_m_reg_s_in[i][75:72],
s_m_reg_s_in[i][95:92], s_m_reg_s_in[i][83:76],
s_m_reg_s_in[i][67:60], s_m_reg_s_in[i][51:48],
s_m_reg_s_in[i][71:68], s_m_reg_s_in[i][59:52],
s_m_reg_s_in[i][43:36], s_m_reg_s_in[i][27:24],
s_m_reg_s_in[i][47:44], s_m_reg_s_in[i][35:28],
s_m_reg_s_in[i][19:12], s_m_reg_s_in[i][03:00],
s_m_reg_s_in[i][23:20], s_m_reg_s_in[i][11:4]};
end
end
推理过程:
需要将原本的
改成
也就是说,原本是从12字节变成8字节
现在aigis需要从13字节变成8字节
需要结合下面decode过程一起理解,很容易算错,建议检验一下


修改的代码:
KeyGen_Encode_sk: begin
//-- 512 coefficients require 64 addresses
for (i=0; i<64; i=i+1) begin
s_m_reg[i*104 +: 104] <= {s_m_reg_s_in[i][98:91],
s_m_reg_s_in[i][80:78],
s_m_reg_s_in[i][103:99],
s_m_reg_s_in[i][88:81],
s_m_reg_s_in[i][70:65],
s_m_reg_s_in[i][90:89],
s_m_reg_s_in[i][52],
s_m_reg_s_in[i][77:71],
s_m_reg_s_in[i][60:53],
s_m_reg_s_in[i][42:39],
s_m_reg_s_in[i][64:61],
s_m_reg_s_in[i][50:43],
s_m_reg_s_in[i][32:26],
s_m_reg_s_in[i][51],
s_m_reg_s_in[i][14:13],
s_m_reg_s_in[i][38:33],
s_m_reg_s_in[i][22:15],
s_m_reg_s_in[i][04:00],
s_m_reg_s_in[i][25:23],
s_m_reg_s_in[i][12:5],
};
end
end
3.算法4中 KeyGen_Encode_pk参数修改
原来的代码:
KeyGen_Encode_pk: begin
if (cnt == 4'd0) begin
rho_reg <= g_rho;
end
for (i=0; i<64; i=i+1) begin
t_c_reg[i*96 +: 96] <= {t_c_reg_t_in[i][91:84], t_c_reg_t_in[i][75:72],
t_c_reg_t_in[i][95:92], t_c_reg_t_in[i][83:76],
t_c_reg_t_in[i][67:60], t_c_reg_t_in[i][51:48],
t_c_reg_t_in[i][71:68], t_c_reg_t_in[i][59:52],
t_c_reg_t_in[i][43:36], t_c_reg_t_in[i][27:24],
t_c_reg_t_in[i][47:44], t_c_reg_t_in[i][35:28],
t_c_reg_t_in[i][19:12], t_c_reg_t_in[i][03:00],
t_c_reg_t_in[i][23:20], t_c_reg_t_in[i][11:4]};
end
end
需要将原本的
改成
也就是说,原本是从12位变成8位
现在aigis需要从10位变成8位,且总共的位数是80位
类似kyber的 Enc_Encode_c
修改的代码:
KeyGen_Encode_pk: begin
if (cnt == 4'd0) begin
rho_reg <= g_rho;
end
for (i=0; i<64; i=i+1) begin
t_c_reg[i*80 +: 80] <= {t_c_reg_t_in[i][77:70],
t_c_reg_t_in[i][65:60],
t_c_reg_t_in[i][79:78],
t_c_reg_t_in[i][53:50],
t_c_reg_t_in[i][69:66],
t_c_reg_t_in[i][41:40],
t_c_reg_t_in[i][59:54],
t_c_reg_t_in[i][49:42],
t_c_reg_t_in[i][37:30],
t_c_reg_t_in[i][25:20],
t_c_reg_t_in[i][39:38],
t_c_reg_t_in[i][13:10],
t_c_reg_t_in[i][29:26],
t_c_reg_t_in[i][01:00],
t_c_reg_t_in[i][19:14],
t_c_reg_t_in[i][09:02]};
end
end
4.算法 5: Aigis-pke.Enc(pk, µ; r):加密算法中 Enc_Encode_c参数修改
需要将原本的
改成
也就是说,原本是c1从10位变成8位,总共80位;aigis需要改成9位变成8位,总共72位
c2从4位变成8位,总共32位;aigis需要改成3位变成8位,总共24位
推理过程:

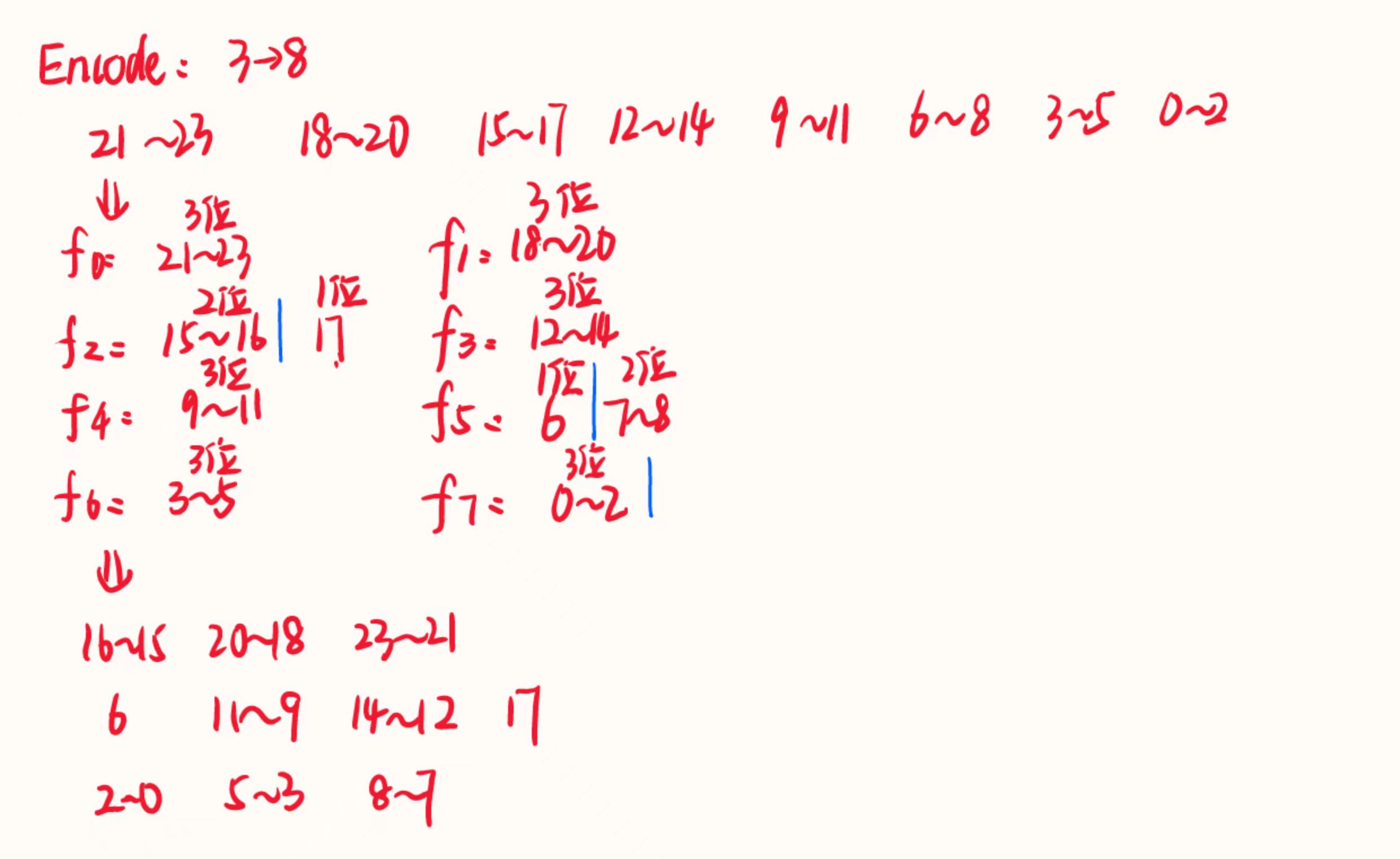
原来的代码 位置顺序:
Enc_Encode_c: begin
//-- c1:10*256*2, each coefficient is 10b, a total of 256*2 coefficients;
//-- Each pass has 8 coefficients, and it needs to be passed 64 times
for (i=0; i<64; i=i+1) begin
t_c_reg[(i*80+32*32) +: 80] <= {t_c_reg_u_in[i][77:70],
t_c_reg_u_in[i][65:60],
t_c_reg_u_in[i][79:78],
t_c_reg_u_in[i][53:50],
t_c_reg_u_in[i][69:66],
t_c_reg_u_in[i][41:40],
t_c_reg_u_in[i][59:54],
t_c_reg_u_in[i][49:42],
t_c_reg_u_in[i][37:30],
t_c_reg_u_in[i][25:20],
t_c_reg_u_in[i][39:38],
t_c_reg_u_in[i][13:10],
t_c_reg_u_in[i][29:26],
t_c_reg_u_in[i][01:00],
t_c_reg_u_in[i][19:14],
t_c_reg_u_in[i][09:02]};
end
//-- c2:4*256, each coefficient is 4b, a total of 256 coefficients;
//-- Each pass has 8 coefficients, and it needs to be passed 32 times
for (i=0; i<32; i=i+1) begin
t_c_reg[i*32 +: 32] <= {t_c_reg_v_in[i][27:24], t_c_reg_v_in[i][31:28],
t_c_reg_v_in[i][19:16], t_c_reg_v_in[i][23:20],
t_c_reg_v_in[i][11:08], t_c_reg_v_in[i][15:12],
t_c_reg_v_in[i][03:00], t_c_reg_v_in[i][07:04]};
end
end
原来的代码 逻辑:
Enc_Encode_c: begin
if (cnt == 7'd0) begin
dtype = 4'd10;
ram_raddr = `RAM_6_OFFSET + cnt;
end else if (cnt < 7'd64) begin
dtype = 4'd10;
ram_raddr = `RAM_6_OFFSET + cnt;
t_c_reg_u_in[64-cnt] = comp_out_d10;
end else if (cnt == 7'd64) begin
dtype = 4'd4;
ram_raddr = `RAM_9_OFFSET + cnt - 7'd64;
t_c_reg_u_in[64-cnt] = comp_out_d10;
end else begin
dtype = 4'd4;
ram_raddr = `RAM_9_OFFSET + cnt - 7'd64;
t_c_reg_v_in[96-cnt] = comp_out_d4;
end
last_cycle = cnt == 7'd96;
修改的代码:
Enc_Encode_c: begin
//-- c1:9*256*2, each coefficient is 9b, a total of 256*2 coefficients;
//-- Each pass has 8 coefficients, and it needs to be passed 64 times
for (i=0; i<64; i=i+1) begin
t_c_reg[(i*72+24*32) +: 72] <= {t_c_reg_u_in[i][70:63],
t_c_reg_u_in[i][60:54],
t_c_reg_u_in[i][71],
t_c_reg_u_in[i][50:45],
t_c_reg_u_in[i][62:61],
t_c_reg_u_in[i][40:36],
t_c_reg_u_in[i][53:51],
t_c_reg_u_in[i][30:27],
t_c_reg_u_in[i][44:41],
t_c_reg_u_in[i][20:18],
t_c_reg_u_in[i][35:31],
t_c_reg_u_in[i][10:09],
t_c_reg_u_in[i][26:21],
t_c_reg_u_in[i][00],
t_c_reg_u_in[i][17:11],
t_c_reg_u_in[i][08:01]};
end
//-- c2:3*256, each coefficient is 3b, a total of 256 coefficients;
//-- Each pass has 8 coefficients, and it needs to be passed 32 times
for (i=0; i<32; i=i+1) begin
t_c_reg[i*24 +: 24] <= {t_c_reg_v_in[i][16:15], t_c_reg_v_in[i][20:18],t_c_reg_v_in[i][23:21],
t_c_reg_v_in[i][06], t_c_reg_v_in[i][11:9],t_c_reg_v_in[i][14:12], t_c_reg_v_in[i][17],
t_c_reg_v_in[i][02:00], t_c_reg_v_in[i][05:03],t_c_reg_v_in[i][08:07]};
end
end
修改的代码 逻辑:
Enc_Encode_c: begin
if (cnt == 7'd0) begin
dtype = 4'd9;
ram_raddr = `RAM_6_OFFSET + cnt;
end else if (cnt < 7'd64) begin
dtype = 4'd9;
ram_raddr = `RAM_6_OFFSET + cnt;
t_c_reg_u_in[64-cnt] = comp_out_d10;
end else if (cnt == 7'd64) begin
dtype = 4'd3;
ram_raddr = `RAM_9_OFFSET + cnt - 7'd64;
t_c_reg_u_in[64-cnt] = comp_out_d10;
end else begin
dtype = 4'd3;
ram_raddr = `RAM_9_OFFSET + cnt - 7'd64;
t_c_reg_v_in[96-cnt] = comp_out_d4;
end
last_cycle = cnt == 7'd96;
5.算法 6: Aigis-pke.Dec(sk, c):解密算法中 Dec_Encode_m参数修改
需要将原本的
改成
也就是说,原本是m从1位变成8位,总共8位;aigis需要改成1位变成8位,总共8位,所以其实不变
6.算法 5: Aigis-pke.Enc(pk, µ; r):加密算法 中 Enc_Decode_pk参数修改
需要将原本的
改成
也就是说,原本是pk从8位变成12位,总共96位;aigis需要改成8位变成13位,总共104位
推理过程:


原来的代码:
//-- assign t_c_reg_t[j] = t_c_reg[(j*96+95):(j*96)];
//-- Coefficients are stored in big-endian mode, and vectors with high-level labels store low-power coefficients
assign t_c_reg_t[j] = {t_c_reg[(j*96+83):(j*96+80)], t_c_reg[(j*96+95):(j*96+88)],
t_c_reg[(j*96+79):(j*96+72)], t_c_reg[(j*96+87):(j*96+84)],
t_c_reg[(j*96+59):(j*96+56)], t_c_reg[(j*96+71):(j*96+64)],
t_c_reg[(j*96+55):(j*96+48)], t_c_reg[(j*96+63):(j*96+60)],
t_c_reg[(j*96+35):(j*96+32)], t_c_reg[(j*96+47):(j*96+40)],
t_c_reg[(j*96+31):(j*96+24)], t_c_reg[(j*96+39):(j*96+36)],
t_c_reg[(j*96+11):(j*96+08)], t_c_reg[(j*96+23):(j*96+16)],
t_c_reg[(j*96+07):(j*96+00)], t_c_reg[(j*96+15):(j*96+12)]};
修改的代码:
//-- assign t_c_reg_t[j] = t_c_reg[(j*104+103):(j*104)];
//-- Coefficients are stored in big-endian mode, and vectors with high-level labels store low-power coefficients
assign t_c_reg_t[j] = {t_c_reg[(j*104+92):(j*104+88)], t_c_reg[(j*104+103):(j*104+96)],
t_c_reg[(j*104+73):(j*104+72)], t_c_reg[(j*104+87):(j*104+80)], t_c_reg[(j*104+95):(j*104+93)],
t_c_reg[(j*104+70):(j*104+64)], t_c_reg[(j*104+79):(j*104+74)],
t_c_reg[(j*104+51):(j*104+48)], t_c_reg[(j*104+63):(j*104+56)],t_c_reg[(j*104+71)],
t_c_reg[(j*104+32)], t_c_reg[(j*104+47):(j*104+40)],t_c_reg[(j*104+55):(j*104+52)],
t_c_reg[(j*104+29):(j*104+24)], t_c_reg[(j*104+39):(j*104+33)],
t_c_reg[(j*104+10):(j*104+08)], t_c_reg[(j*104+23):(j*104+16)],t_c_reg[(j*104+31):(j*104+30)],
t_c_reg[(j*104+07):(j*104+00)], t_c_reg[(j*104+15):(j*104+11)]};
7.算法 5: Aigis-pke.Enc(pk, µ; r):加密算法 中 Enc_Decode_m参数修改
需要将原本的
改成
也就是说,原本是m从8位变成1位,总共8位;aigis也是8位变成1位,总共8位,所以不需要改变
8.算法 6: Aigis-pke.Dec(sk, c):解密算法 中 Dec_Decode_sk参数修改
需要将原本的
改成
也就是说,原本是m从8位变成12位,总共96位;aigis是从8位变成13位,总共104位,和上面 6.算法 5: Aigis-pke.Enc(pk, µ; r):加密算法 中 Enc_Decode_pk参数修改 相似
原来的代码:
//-- assign s_m_reg_s[j] = s_m_reg[(j*96+95):(j*96)];
//-- Coefficients are stored in big-endian mode, and vectors with high-level labels store low-power coefficients
assign s_m_reg_s[j] = {s_m_reg[(j*96+83):(j*96+80)], s_m_reg[(j*96+95):(j*96+88)],
s_m_reg[(j*96+79):(j*96+72)], s_m_reg[(j*96+87):(j*96+84)],
s_m_reg[(j*96+59):(j*96+56)], s_m_reg[(j*96+71):(j*96+64)],
s_m_reg[(j*96+55):(j*96+48)], s_m_reg[(j*96+63):(j*96+60)],
s_m_reg[(j*96+35):(j*96+32)], s_m_reg[(j*96+47):(j*96+40)],
s_m_reg[(j*96+31):(j*96+24)], s_m_reg[(j*96+39):(j*96+36)],
s_m_reg[(j*96+11):(j*96+08)], s_m_reg[(j*96+23):(j*96+16)],
s_m_reg[(j*96+07):(j*96+00)], s_m_reg[(j*96+15):(j*96+12)]};
修改的代码:
//-- assign s_m_reg_s[j] = s_m_reg[(j*104+103):(j*104)];
//-- Coefficients are stored in big-endian mode, and vectors with high-level labels store low-power coefficients
assign s_m_reg_s[j] = {s_m_reg[(j*104+92):(j*104+88)], s_m_reg[(j*104+103):(j*104+96)],
s_m_reg[(j*104+73):(j*104+72)], s_m_reg[(j*104+87):(j*104+80)], s_m_reg[(j*104+95):(j*104+93)],
s_m_reg[(j*104+70):(j*104+64)], s_m_reg[(j*104+79):(j*104+74)],
s_m_reg[(j*104+51):(j*104+48)], s_m_reg[(j*104+63):(j*104+56)],s_m_reg[(j*104+71)],
s_m_reg[(j*104+32)], s_m_reg[(j*104+47):(j*104+40)],s_m_reg[(j*104+55):(j*104+52)],
s_m_reg[(j*104+29):(j*104+24)], s_m_reg[(j*104+39):(j*104+33)],
s_m_reg[(j*104+10):(j*104+08)], s_m_reg[(j*104+23):(j*104+16)],s_m_reg[(j*104+31):(j*104+30)],
s_m_reg[(j*104+07):(j*104+00)], s_m_reg[(j*104+15):(j*104+11)]};
9.算法 6: Aigis-pke.Dec(sk, c):解密算法 中 Dec_Decode_c参数修改
需要将原本的
改成
也就是说,原本是c从8位变成10+4位,总共80+32位;aigis是从8位变成9+3位,总共72+24位
根据aigis-enc中的描述可知此处第一行的c是c1,第二行的c是c2。

推理过程:


原来的代码Dec_Decode_c1:
//-- assign t_c_reg_u[j] = decode_u_reg[(j*80+79):(j*80)];
//-- Coefficients are stored in big-endian mode, and vectors with high-level labels store low-power coefficients
assign t_c_reg_u[j] = {decode_u_reg[(j*80+65):(j*80+64)], decode_u_reg[(j*80+79):(j*80+72)],
decode_u_reg[(j*80+59):(j*80+56)], decode_u_reg[(j*80+71):(j*80+66)],
decode_u_reg[(j*80+53):(j*80+48)], decode_u_reg[(j*80+63):(j*80+60)],
decode_u_reg[(j*80+47):(j*80+40)], decode_u_reg[(j*80+55):(j*80+54)],
decode_u_reg[(j*80+25):(j*80+24)], decode_u_reg[(j*80+39):(j*80+32)],
decode_u_reg[(j*80+19):(j*80+16)], decode_u_reg[(j*80+31):(j*80+26)],
decode_u_reg[(j*80+13):(j*80+08)], decode_u_reg[(j*80+23):(j*80+20)],
decode_u_reg[(j*80+07):(j*80+00)], decode_u_reg[(j*80+15):(j*80+14)]};
修改的代码Dec_Decode_c1:
//-- assign t_c_reg_u[j] = decode_u_reg[(j*72+71):(j*72)];
//-- Coefficients are stored in big-endian mode, and vectors with high-level labels store low-power coefficients
assign t_c_reg_u[j] = {decode_u_reg[(j*72+56)], decode_u_reg[(j*72+71):(j*72+64)],
decode_u_reg[(j*72+49):(j*72+48)], decode_u_reg[(j*72+63):(j*72+57)],
decode_u_reg[(j*72+42):(j*72+40)], decode_u_reg[(j*72+55):(j*72+50)],
decode_u_reg[(j*72+35):(j*72+32)], decode_u_reg[(j*72+47):(j*72+43)],
decode_u_reg[(j*72+28):(j*72+24)], decode_u_reg[(j*72+39):(j*72+36)],
decode_u_reg[(j*72+21):(j*72+16)], decode_u_reg[(j*72+31):(j*72+29)],
decode_u_reg[(j*72+14):(j*72+08)], decode_u_reg[(j*72+23):(j*72+22)],
decode_u_reg[(j*72+07):(j*72+00)], decode_u_reg[(j*72+15)]};
原来的代码Dec_Decode_c2:
Dec_Decode_c: begin
ram_we = ((cnt != 7'd0) && (cnt != 7'd65)) ? 1'b1 : 1'b0;
ram_waddr = (cnt < 7'd65) ? (`RAM_12_OFFSET + cnt - 10'd1) : (`RAM_12_OFFSET + cnt - 10'd2);
ram_wdata = decomp_out_data;
dtype = (cnt < 7'd65) ? 4'd10 : 4'd4;
if (cnt < 7'd64) begin
decomp_in_d10 = t_c_reg_u[63-cnt];
end else if (cnt > 7'd64) begin
decomp_in_d4 = t_c_reg_v[96-cnt];
end
last_cycle = cnt == 7'd97;
修改的代码Dec_Decode_c2:
Dec_Decode_c: begin
ram_we = ((cnt != 7'd0) && (cnt != 7'd65)) ? 1'b1 : 1'b0;
ram_waddr = (cnt < 7'd65) ? (`RAM_12_OFFSET + cnt - 10'd1) : (`RAM_12_OFFSET + cnt - 10'd2);
ram_wdata = decomp_out_data;
dtype = (cnt < 7'd65) ? 4'd9 : 4'd3;
if (cnt < 7'd64) begin
decomp_in_d10 = t_c_reg_u[63-cnt];
end else if (cnt > 7'd64) begin
decomp_in_d4 = t_c_reg_v[96-cnt];
end
last_cycle = cnt == 7'd97;
原来的代码 逻辑:
//-- assign t_c_reg_v[j] = decode_v_reg[(j*32+31):(j*32)];
//-- Coefficients are stored in big-endian mode, and vectors with high-level labels store low-power coefficients
assign t_c_reg_v[j] = {decode_v_reg[(j*32+27):(j*32+24)], decode_v_reg[(j*32+31):(j*32+28)],
decode_v_reg[(j*32+19):(j*32+16)], decode_v_reg[(j*32+23):(j*32+20)],
decode_v_reg[(j*32+11):(j*32+08)], decode_v_reg[(j*32+15):(j*32+12)],
decode_v_reg[(j*32+03):(j*32+00)], decode_v_reg[(j*32+07):(j*32+04)]};
修改的代码 逻辑:
//-- assign t_c_reg_v[j] = decode_v_reg[(j*24+33):(j*24)];
//-- Coefficients are stored in big-endian mode, and vectors with high-level labels store low-power coefficients
assign t_c_reg_v[j] = {decode_v_reg[(j*24+18):(j*24+16)], decode_v_reg[(j*24+21):(j*24+19)],
decode_v_reg[(j*24+8)], decode_v_reg[(j*24+23):(j*24+22)],
decode_v_reg[(j*24+11):(j*24+09)], decode_v_reg[(j*24+14):(j*24+12)],
decode_v_reg[(j*24+01):(j*24+00)], decode_v_reg[(j*24+15)],
decode_v_reg[(j*24+04):(j*24+02)], decode_v_reg[(j*24+07):(j*24+05)]};
10.修改compress的参数
kyber文档中表示压缩和解压缩的功能其实和aigis的一样,具体如下两张图:


compress部分:
- kyber 进行大到小的模切换是从q=3329切换到 、 、
- aigis 进行大到小的模切换是从q=7681切换到 、 、
decompress部分:
- kyber 进行大到小的模切换是从 、 、 切换到q=3329
- aigis 进行大到小的模切换是从 、、、 切换到q=7681
compress的位数修改 compress.v文件修改
原来的代码
(
input clk,
input rst,
input [95:0] in_data,
output [7:0] out_data_d1,
output [31:0] out_data_d4,
output [79:0] out_data_d10
);
//-- input reg
reg [11:0] in_reg [7:0];
reg [16:0] in_reg4 [7:0];
reg [16:0] in_reg4_d [7:0];
reg [19:0] in_reg10 [7:0];
reg [19:0] in_reg10_d [7:0];
reg [9:0] out_reg10 [7:0];
wire [12:0] subtrahend4;
wire [11:0] subtrahend10;
修改的代码
(
input clk,
input rst,
input [103:0] in_data, //13*8
output [7:0] out_data_d1, //1*8
output [23:0] out_data_d4, //3*8
output [71:0] out_data_d10 //9*8
);
//-- input reg
reg [12:0] in_reg [7:0]; //13位
reg [16:0] in_reg4 [7:0];
reg [16:0] in_reg4_d [7:0];
reg [19:0] in_reg10 [7:0];
reg [19:0] in_reg10_d [7:0];
reg [9:0] out_reg10 [7:0];
wire [12:0] subtrahend4;
wire [11:0] subtrahend10;
a. 从q=3329切换到 修改成 从q=7681切换到
原来的代码
//-- in_reg
always @(posedge clk or posedge rst) begin
if (rst) begin
in_reg[0] <= 12'd0;
in_reg[1] <= 12'd0;
in_reg[2] <= 12'd0;
in_reg[3] <= 12'd0;
in_reg[4] <= 12'd0;
in_reg[5] <= 12'd0;
in_reg[6] <= 12'd0;
in_reg[7] <= 12'd0;
end else begin
in_reg[0] <= in_data[11:00];
in_reg[1] <= in_data[23:12];
in_reg[2] <= in_data[35:24];
in_reg[3] <= in_data[47:36];
in_reg[4] <= in_data[59:48];
in_reg[5] <= in_data[71:60];
in_reg[6] <= in_data[83:72];
in_reg[7] <= in_data[95:84];
end
end
//assign out_data_d1 = { mul_out[7][22], mul_out[6][22], mul_out[5][22], mul_out[4][22],
// mul_out[3][22], mul_out[2][22], mul_out[1][22], mul_out[0][22] } ; // mul_out >> 22
//-- Move directly to the right is rounded down, and the comparison size is rounded
//-- 0~3328 maps to 0~1, [0, 0.5) is 0, [0.5, 1.5) is 1, [1.5, 2) is 0; 3329 corresponds to 0.5 points and 1.5 points, which are 832.25 and 2496.75
assign out_data_d1[7] = (in_reg[7] > 12'd832) && (in_reg[7] < 12'd2497);
assign out_data_d1[6] = (in_reg[6] > 12'd832) && (in_reg[6] < 12'd2497);
assign out_data_d1[5] = (in_reg[5] > 12'd832) && (in_reg[5] < 12'd2497);
assign out_data_d1[4] = (in_reg[4] > 12'd832) && (in_reg[4] < 12'd2497);
assign out_data_d1[3] = (in_reg[3] > 12'd832) && (in_reg[3] < 12'd2497);
assign out_data_d1[2] = (in_reg[2] > 12'd832) && (in_reg[2] < 12'd2497);
assign out_data_d1[1] = (in_reg[1] > 12'd832) && (in_reg[1] < 12'd2497);
assign out_data_d1[0] = (in_reg[0] > 12'd832) && (in_reg[0] < 12'd2497);
修改的逻辑
kyber: 0~3328 maps to 0~1, [0, 0.5) is 0, [0.5, 1.5) is 1, [1.5, 2) is 0; 3329 corresponds to 0.5 points and 1.5 points, which are 3329*0.5/2=832.25 and 3329*1.5/2=2496.75
aigis: 0~7681 maps to 0~1, [0, 0.5) is 0, [0.5, 1.5) is 1, [1.5, 2) is 0; 7681 corresponds to 0.5 points and 1.5 points, which are 7681*0.5/2=1920.25 and 7681*1.5/2=5760.75
修改的代码
//-- in_reg
always @(posedge clk or posedge rst) begin
if (rst) begin
in_reg[0] <= 13'd0;
in_reg[1] <= 13'd0;
in_reg[2] <= 13'd0;
in_reg[3] <= 13'd0;
in_reg[4] <= 13'd0;
in_reg[5] <= 13'd0;
in_reg[6] <= 13'd0;
in_reg[7] <= 13'd0;
end else begin
in_reg[0] <= in_data[12:00];
in_reg[1] <= in_data[25:13];
in_reg[2] <= in_data[38:26];
in_reg[3] <= in_data[51:39];
in_reg[4] <= in_data[64:52];
in_reg[5] <= in_data[77:65];
in_reg[6] <= in_data[90:78];
in_reg[7] <= in_data[103:91];
end
end
//-- Move directly to the right is rounded down, and the comparison size is rounded
//-- 0~7681 maps to 0~1, [0, 0.5) is 0, [0.5, 1.5) is 1, [1.5, 2) is 0; 7681 corresponds to 0.5 points and 1.5 points, which are 1920.25 and 5760.75
assign out_data_d1[7] = (in_reg[7] > 12'd1920) && (in_reg[7] < 12'd5761);
assign out_data_d1[6] = (in_reg[6] > 12'd1920) && (in_reg[6] < 12'd5761);
assign out_data_d1[5] = (in_reg[5] > 12'd1920) && (in_reg[5] < 12'd5761);
assign out_data_d1[4] = (in_reg[4] > 12'd1920) && (in_reg[4] < 12'd5761);
assign out_data_d1[3] = (in_reg[3] > 12'd1920) && (in_reg[3] < 12'd5761);
assign out_data_d1[2] = (in_reg[2] > 12'd1920) && (in_reg[2] < 12'd5761);
assign out_data_d1[1] = (in_reg[1] > 12'd1920) && (in_reg[1] < 12'd5761);
assign out_data_d1[0] = (in_reg[0] > 12'd1920) && (in_reg[0] < 12'd5761);
- kyber 进行大到小的模切换是从q=3329切换到 、 、
- aigis 进行大到小的模切换是从q=7681切换到 、 、
b. 从q=3329切换到 修改成 从q=7681切换到
原来的代码
assign subtrahend4 = {8'd208, 5'd0};
//-- in_reg4: 8 组 17 位寄存器,用于存储处理后的输入数据
always @(posedge clk or posedge rst) begin
if (rst) begin
// 复位时,所有寄存器清零
in_reg4[0] <= 17'd0;
in_reg4[1] <= 17'd0;
in_reg4[2] <= 17'd0;
in_reg4[3] <= 17'd0;
in_reg4[4] <= 17'd0;
in_reg4[5] <= 17'd0;
in_reg4[6] <= 17'd0;
in_reg4[7] <= 17'd0;
end else begin
// 非复位时,更新寄存器值
in_reg4[0] <= in_reg4_d[0];
in_reg4[1] <= in_reg4_d[1];
in_reg4[2] <= in_reg4_d[2];
in_reg4[3] <= in_reg4_d[3];
in_reg4[4] <= in_reg4_d[4];
in_reg4[5] <= in_reg4_d[5];
in_reg4[6] <= in_reg4_d[6];
in_reg4[7] <= in_reg4_d[7];
end
end
//-- 组合逻辑块:计算 in_reg4_d
always @(in_data) begin
// **拆分 in_data,每 12 位一组,并加上 103**
in_reg4_d[0] = {5'd0, (in_data[11:00] + 12'd103)};
in_reg4_d[1] = {5'd0, (in_data[23:12] + 12'd103)};
in_reg4_d[2] = {5'd0, (in_data[35:24] + 12'd103)};
in_reg4_d[3] = {5'd0, (in_data[47:36] + 12'd103)};
in_reg4_d[4] = {5'd0, (in_data[59:48] + 12'd103)};
in_reg4_d[5] = {5'd0, (in_data[71:60] + 12'd103)};
in_reg4_d[6] = {5'd0, (in_data[83:72] + 12'd103)};
in_reg4_d[7] = {5'd0, (in_data[95:84] + 12'd103)};
// **循环处理 in_reg4_d,使其进行5次左移并进行修正**
for (i=0; i<8; i=i+1) begin // 处理 8 个寄存器数据
for (j=0; j<5; j=j+1) begin // 进行 5 次移位和修正
in_reg4_d[i] = {in_reg4_d[i][15:0], 1'b0};// **左移 1 位**
if (in_reg4_d[i] >= subtrahend4) begin
// **如果值大于等于 subtrahend4,则执行减法修正**
in_reg4_d[i] = in_reg4_d[i] - subtrahend4 + 1'b1;
end
end
end
end
//assign out_data_d4 = {mul_out[7][22:19], mul_out[6][22:19], mul_out[5][22:19], mul_out[4][22:19],
// mul_out[3][22:19], mul_out[2][22:19], mul_out[1][22:19], mul_out[0][22:19]}; // mul_out >> 19
//-- 输出信号:仅保留 in_reg4 每个寄存器的低 4 位,并拼接为 32 位输出
assign out_data_d4 = {in_reg4[7][3:0], in_reg4[6][3:0], in_reg4[5][3:0], in_reg4[4][3:0],
in_reg4[3][3:0], in_reg4[2][3:0], in_reg4[1][3:0], in_reg4[0][3:0]};
修改的逻辑
kyber: 3329
aigis: 0~7681 maps to 0~1, [0, 0.5) is 0, [0.5, 1.5) is 1, [1.5, 2) is 0; 7681 corresponds to 0.5 points and 1.5 points, which are 7681*0.5/2=1920.25 and 7681*1.5/2=5760.75
修改的代码
assign subtrahend4 = {8'd208, 5'd0};
//-- in_reg4: 8 组 17 位寄存器,用于存储处理后的输入数据
always @(posedge clk or posedge rst) begin
if (rst) begin
// 复位时,所有寄存器清零
in_reg4[0] <= 17'd0;
in_reg4[1] <= 17'd0;
in_reg4[2] <= 17'd0;
in_reg4[3] <= 17'd0;
in_reg4[4] <= 17'd0;
in_reg4[5] <= 17'd0;
in_reg4[6] <= 17'd0;
in_reg4[7] <= 17'd0;
end else begin
// 非复位时,更新寄存器值
in_reg4[0] <= in_reg4_d[0];
in_reg4[1] <= in_reg4_d[1];
in_reg4[2] <= in_reg4_d[2];
in_reg4[3] <= in_reg4_d[3];
in_reg4[4] <= in_reg4_d[4];
in_reg4[5] <= in_reg4_d[5];
in_reg4[6] <= in_reg4_d[6];
in_reg4[7] <= in_reg4_d[7];
end
end
//-- 组合逻辑块:计算 in_reg4_d
always @(in_data) begin
// **拆分 in_data,每 12 位一组,并加上 103**
in_reg4_d[0] = {5'd0, (in_data[11:00] + 12'd103)};
in_reg4_d[1] = {5'd0, (in_data[23:12] + 12'd103)};
in_reg4_d[2] = {5'd0, (in_data[35:24] + 12'd103)};
in_reg4_d[3] = {5'd0, (in_data[47:36] + 12'd103)};
in_reg4_d[4] = {5'd0, (in_data[59:48] + 12'd103)};
in_reg4_d[5] = {5'd0, (in_data[71:60] + 12'd103)};
in_reg4_d[6] = {5'd0, (in_data[83:72] + 12'd103)};
in_reg4_d[7] = {5'd0, (in_data[95:84] + 12'd103)};
// **循环处理 in_reg4_d,使其进行5次左移并进行修正**
for (i=0; i<8; i=i+1) begin // 处理 8 个寄存器数据
for (j=0; j<5; j=j+1) begin // 进行 5 次移位和修正
in_reg4_d[i] = {in_reg4_d[i][15:0], 1'b0};// **左移 1 位**
if (in_reg4_d[i] >= subtrahend4) begin
// **如果值大于等于 subtrahend4,则执行减法修正**
in_reg4_d[i] = in_reg4_d[i] - subtrahend4 + 1'b1;
end
end
end
end
//assign out_data_d4 = {mul_out[7][22:19], mul_out[6][22:19], mul_out[5][22:19], mul_out[4][22:19],
// mul_out[3][22:19], mul_out[2][22:19], mul_out[1][22:19], mul_out[0][22:19]}; // mul_out >> 19
//-- 输出信号:仅保留 in_reg4 每个寄存器的低 4 位,并拼接为 32 位输出
assign out_data_d4 = {in_reg4[7][3:0], in_reg4[6][3:0], in_reg4[5][3:0], in_reg4[4][3:0],
in_reg4[3][3:0], in_reg4[2][3:0], in_reg4[1][3:0], in_reg4[0][3:0]};
c. 从q=3329切换到修改成 从q=7681切换到
4 Aigis-pke.KeyGen() 和 Kyber.CPAPKE.KeyGen() 密钥生成算法的比较
4.1 密钥和参数的大小
-
Aigis-pke:
- 公钥的大小是 ,其中 、、 是算法的参数。
- 私钥的大小是 ,其中 是模数。
-
Kyber.CPAPKE:
- 公钥的大小是 。
- 私钥的大小是 。
n都等于256,k都等于2,
对照aigis的表格修改位数
4.2 噪声采样
-
Aigis-pke:
- 使用 从 中采样噪声 和 从 中采样噪声 。
- 这里,噪声 和 的分布是基于不同的 参数,表示不同的噪声幅度或密度。
-
Kyber.CPAPKE:
- 只使用 从 中采样噪声 和 ,并且 用于定义噪声分布。
推理过程:
所以修改其中对应控制选择CBD参数部分即可,但aigis中eta2对应12,则需要如下图将两个CBD相加
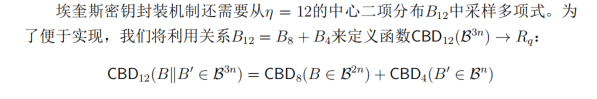
- 只使用 从 中采样噪声 和 ,并且 用于定义噪声分布。
原来的代码:
CBD_st_e0: begin
CBD_num = (kyber_mode == kyber512) ? 2'd1 : 2'd2;
CBD_ram_w_start_offset = ram_6_offset;
CBD_input = {G_sigma,8'd2};
CBD_active = ~CBD_finsh_reg;
CBD_rst = CBD_finsh_reg;
CBD_nstate = CBD_finsh_reg ? CBD_st_e1 : CBD_st_e0;
CBD_E_finish[0] = CBD_finsh_reg;
end
CBD_st_e1: begin
CBD_num = (kyber_mode == kyber512) ? 2'd1 : 2'd2;
CBD_ram_w_start_offset = ram_7_offset;
CBD_input = {G_sigma,8'd3};
CBD_active = ~CBD_finsh_reg;
CBD_rst = CBD_finsh_reg;
CBD_nstate = CBD_finsh_reg ? CBD_st_INTT : CBD_st_e1;
CBD_E_finish[1] = CBD_finsh_reg;
CBD_SAMPLE_finish = CBD_finsh_reg;
end
修改的代码:
CBD_st_e00: begin
CBD_num = 2'd2;
CBD_ram_w_start_offset = ram_6_offset;
CBD_input = {G_sigma,8'd2};
CBD_active = ~CBD_finsh_reg;
CBD_rst = CBD_finsh_reg;
CBD_nstate = CBD_finsh_reg ? CBD_st_e1 : CBD_st_e0;
CBD_E_finish[0] = CBD_finsh_reg;
end
CBD_st_e01: begin
CBD_num = 2'd2;
CBD_ram_w_start_offset = ram_7_offset;
CBD_input = {G_sigma,8'd3};
CBD_active = ~CBD_finsh_reg;
CBD_rst = CBD_finsh_reg;
CBD_nstate = CBD_finsh_reg ? CBD_st_INTT : CBD_st_e1;
CBD_E_finish[1] = CBD_finsh_reg;
CBD_SAMPLE_finish = CBD_finsh_reg;
end
CBD_st_e10: begin
CBD_num = 2'd3;
CBD_ram_w_start_offset = ram_6_offset;
CBD_input = {G_sigma,8'd2};
CBD_active = ~CBD_finsh_reg;
CBD_rst = CBD_finsh_reg;
CBD_nstate = CBD_finsh_reg ? CBD_st_e1 : CBD_st_e0;
CBD_E_finish[0] = CBD_finsh_reg;
end
CBD_st_e11: begin
CBD_num = 2'd3;
CBD_ram_w_start_offset = ram_7_offset;
CBD_input = {G_sigma,8'd3};
CBD_active = ~CBD_finsh_reg;
CBD_rst = CBD_finsh_reg;
CBD_nstate = CBD_finsh_reg ? CBD_st_INTT : CBD_st_e1;
CBD_E_finish[1] = CBD_finsh_reg;
CBD_SAMPLE_finish = CBD_finsh_reg;
end
//然后需要弄一个相加的
4.3 NTT 的使用与逆 NTT 的使用
Aigis-enc:对 进行 NTT 转换,结果在时域中处理噪声 ; 使用 将结果从频域转换回时域,然后处理噪声。
Kyber :对 和 都进行 NTT 转换,所有操作均在频域完成;无需逆 NTT 操作,直接在频域中加噪声 。
原来的代码:删去如下这一部分
NTT_st_NTT_e0:begin
ram_w_sel_ntt = 1'b1;
ram_r_sel_ntt = 1'b1;
ntt_mode = `FORWARD_NTT_MODE;
ntt_ram_r_offset_a = `RAM_6_OFFSET;
ntt_ram_r_offset_b = `RAM_6_OFFSET;
ntt_ram_w_offset = `RAM_6_OFFSET;
ntt_start_set = ~ntt_finish_reg;
ntt_rst = ntt_finish_reg;
ntt_nstate = ntt_finish_reg ? NTT_st_NTT_e1 : NTT_st_NTT_e0;
end
NTT_st_NTT_e1: begin
ram_w_sel_ntt = 1'b1;
ram_r_sel_ntt = 1'b1;
ntt_mode = `FORWARD_NTT_MODE;
ntt_ram_r_offset_a = `RAM_7_OFFSET;
ntt_ram_r_offset_b = `RAM_7_OFFSET;
ntt_ram_w_offset = `RAM_7_OFFSET;
ntt_start_set = ~ntt_finish_reg;
ntt_rst = ntt_finish_reg;
ntt_se_finish = ntt_finish_reg;
ntt_nstate = ntt_finish_reg ? NTT_st_INTT_2 : NTT_st_NTT_e1;
end
然后对 NTT_st_ADD_t0和NTT_st_ADD_t1这部分的结果做INTT(增加一个INTT的过程),然后再相应的加e0和e1,需要修改掉NTT_st_ADD_e0和NTT_st_ADD_e0两部分(修改两个NTT加的部分)
4.4 编码方式
Aigis-enc: 经过模切换操作 后,将结果压缩到更小的域()。然后通过编码方法 处理 ,最后将其与随机数种子 拼接生成公钥 。
Kyber :公钥 固定使用 12 比特进行编码。
编码已经在上面第三板块修改好了,只需要加入模切换操作
kyber文档中表示压缩的功能其实和aigis的一样,具体如下两张图:
所以加入模切换操作就是在coder.v中加入compress
原来的代码:
KeyGen_Encode_pk: begin
ram_raddr = `RAM_6_OFFSET + cnt;
t_c_reg_t_in[63-cnt] = ram_rdata;
last_cycle = cnt == 7'd63;
end
修改的代码:
KeyGen_Encode_pk: begin
ram_raddr = `RAM_6_OFFSET + cnt;
t_c_reg_t_in[63-cnt] = comp_out_d10;
last_cycle = cnt == 7'd63;
4.3 总结区别
| 方面 | Aigis-enc | Kyber |
|---|---|---|
| NTT 的使用 | 对 进行 NTT 转换,结果在时域中处理噪声 。 | 对 和 都进行 NTT 转换,所有操作均在频域完成。 |
| 逆 NTT 的使用 | 使用 将结果从频域转换回时域,然后处理噪声。 | 无需逆 NTT 操作,直接在频域中加噪声 。 |
| 噪声处理 | 噪声 在时域中加到 。 | 噪声 在频域中加到 。 |
| 编码方式 | 经过舍入操作 后,将结果压缩到更小的域()。然后通过编码方法 处理 ,最后将其与随机数种子 拼接生成公钥 。 | 公钥 固定使用 12 比特进行编码。 |
| 私钥编码 | 私钥编码精度动态调整(),与模数 的大小相关。 | 私钥编码精度固定为 12 比特,标准化更强。 |
| 公钥生成 | 在时域中生成 ,经过域压缩后编码为公钥,与 拼接。 | 在频域中生成 ,模 后直接编码为公钥,与 拼接。 |
| 效率 | 时域与频域的切换可能带来额外开销,效率稍低。 | 频域操作更高效,适合硬件实现。 |
4.4 总结表格
| 特性 | Aigis-pke | Kyber.CPAPKE |
|---|---|---|
| 公钥大小 | ||
| 私钥大小 | ||
| 噪声采样 | 从 和 采样 | 仅从 采样 |
| NTT 变换 | 对矩阵和向量进行 NTT 变换 | 对矩阵和向量进行 NTT 变换 |
| 公钥编码 | 使用 Encodedt 进行编码 |
使用 Encode12 进行编码 |
| 私钥编码 | 使用 Encode⌈log2 q⌉ 进行编码 |
使用 Encode12 进行编码 |
参数值带入后
| 特性 | Aigis-pke | Kyber.CPAPKE |
|---|---|---|
| 公钥大小 | ||
| 私钥大小 | ||
| 噪声采样 | 从 和 采样 | 仅从 采样 |
| NTT 变换 | 对矩阵和向量进行 NTT 变换 | 对矩阵和向量进行 NTT 变换 |
| 公钥编码 | 使用 Encode_10 进行编码 |
使用 Encode12 进行编码 |
| 私钥编码 | 使用 Encode_13_ 进行编码 |
使用 Encode12 进行编码 |
4.5 主要区别:
- 噪声采样:Aigis-pke 使用了两个不同的噪声分布 和 ,而 Kyber.CPAPKE 只使用 。
- 公钥和私钥的编码方式:两者的编码方式不同,尤其是 Aigis-pke 使用了更复杂的编码过程(
Encodedt和Encode⌈log2 q⌉),而 Kyber.CPAPKE 使用了较简单的Encode12。 - 密钥大小:两者的密钥大小公式不同,公钥和私钥的存储要求也不同。
5 Aigis-pke.Enc(pk, µ; r) 和 Kyber.CPAPKE.KeyGen() 加密算法的比较
5.1 输入和参数表示
Aigis-PKE:
- 公钥:
- 明文:
- 随机数:
Kyber.CPAPKE:
- 公钥:
- 明文:
- 随机数:
区别:
- Aigis-PKE 的公钥和明文采用更灵活的表示形式,与参数 和 有关;Kyber.CPAPKE 的明文固定为 位宽。
- Aigis-PKE 的公钥中包含 的信息,而 Kyber.CPAPKE 的公钥为固定大小 。
5.2 公钥解析和矩阵生成
Aigis-PKE:
- 公钥解析:
- 矩阵 的生成通过 ,其中 为随机种子, 为索引。
Kyber.CPAPKE:
- 公钥解析:
- 矩阵 的生成通过 ,其中 和 构成种子。
区别:
-
- 从公钥 中解析出值 ,具体解析方法包括:
- 使用 函数解码 。
- 解码后的结果被从基数 映射到模数 。
- 最终取整操作 将结果舍入。
- 从公钥 中解析出值 ,具体解析方法包括:
-
- 直接从公钥 中解码出 ,解码过程仅基于固定的编码基数 。
5.3 噪声向量的生成
Aigis-PKE:
- 生成随机向量
- 噪声向量 从 采样,使用
Kyber.CPAPKE:
- 同样生成随机向量
- 噪声向量 同样从 采样,使用
区别:
- 噪声生成的核心过程一致,仅在参数(如 )的具体实现上存在差异。
5.4 密文计算
Aigis-PKE:
- 密文编码:
Kyber.CPAPKE:
- 密文编码:
区别:
- Aigis-PKE 的密文计算中, 增加了额外项 ,而 Kyber.CPAPKE 使用 函数对明文解码。
- Aigis-PKE 的密文编码直接采用舍入操作 ,而 Kyber.CPAPKE 使用压缩函数 。
5.5 密钥压缩和参数表示
Aigis-PKE:
- 密文的每部分 分别以 为基进行编码,支持动态压缩。
Kyber.CPAPKE:
- 密文的压缩基数通过 函数确定,较为固定。
5.6 输入输出对比表
| 对比项 | Aigis 加密算法 | Kyber 加密算法 |
|---|---|---|
| 公钥大小 | ||
| 明文大小 | 固定为 | |
| 随机数大小 | 固定为 | |
| 密文大小 |
6.Aigis-pke.Dec(sk, c) 和 Kyber.CPAPKE.Dec(sk, c) 解密算法的比较
1. 输入参数的格式
-
Aigis-pke:
- 私钥 的编码格式为 。
- 密文 的格式为 。
-
Kyber:
- 私钥 的编码格式为 。
- 密文 的格式与 Aigis-pke 相同,为 。
2. 密文向量的处理方式
-
Aigis-pke:
- 使用 对密文进行处理,直接量化到模 的范围。
- 同理,对 也采用类似的解码方式。
-
Kyber:
- 使用 对密文向量进行解压缩,将其从较小的编码范围恢复到模 的范围。
- 同样对 也采用解压缩处理。
区别:Aigis-pke 使用的是直接解码,而 Kyber 还引入了解压缩步骤,是因为 Kyber 的密文在加密时使用了压缩机制,从而需要在解密时进行解压。
3. 私钥的解码方式
-
Aigis-pke:
- 使用 对私钥进行解码,提取数论变换(NTT)域的向量 。
-
Kyber:
- 使用 对私钥进行解码,提取数论变换(NTT)域的向量 。
区别:Aigis-pke 中私钥的编码是基于 ,而 Kyber 中私钥的编码固定为 12 比特。
4. 消息恢复的过程
-
Aigis-pke:
- 使用 来恢复消息。
- 直接将 的结果量化到二进制范围。
-
Kyber:
- 使用 来恢复消息。
- Kyber 中先对 的结果进行压缩 ,然后量化到二进制范围。
区别:Kyber 在消息恢复时引入了压缩步骤,而 Aigis-pke 则没有。
总结表格
| 特性 | Aigis-pke | Kyber |
|---|---|---|
| 私钥格式 | ||
| 密文格式 | ||
| 密文向量处理 | 直接解码到模 的范围 | 先解压缩后恢复到模 的范围 |
| 私钥解码 | 基于 的解码 | 基于固定 12 比特的解码 |
| 消息恢复 | 直接量化到二进制范围 | 先压缩后再量化到二进制范围 |
7.Aigis-enc.KeyGen() 和 Kyber.CCAKEM.KeyGen() 密钥生成算法的比较
| 特性 | Aigis-enc.KeyGen() | Kyber.CCAKEM.KeyGen() |
|---|---|---|
| 公钥大小 | ||
| 私钥大小 | ||
| 随机数大小 | 32 字节 | |
| 底层 PKE 算法 | Aigis-pke.KeyGen() | Kyber.CPAPKE.KeyGen() |
8.Aigis-enc.Encaps(pk)和 Kyber.CCAKEM.Enc(pk)密钥封装算法的比较
| 特性 | Aigis-enc.Encaps | Kyber.CCAKEM.Enc |
|---|---|---|
| 公钥大小 | ||
| 密钥大小 | ||
| 随机数生成 | ||
| 密钥与随机数的生成 | ||
| 加密内容 | 加密 | 加密 |
| 底层加密算法 | Aigis-pke.Enc | Kyber.CPAPKE.Enc |
| 密钥派生 | 哈希函数 | 专门的密钥派生函数 |
Aigis-enc.Decaps 和 Kyber.CCAKEM.Dec 解封装算法的比较
总结表格
| 特性 | Aigis-enc.Decaps | Kyber.CCAKEM.Dec |
|---|---|---|
| 公钥大小 | ||
| 私钥大小 | ||
| 密钥大小 | ||
| 随机数大小 | 32 字节 | |
| 密钥生成与加密 | Aigis-pke.Dec 和 Aigis-pke.Enc | Kyber.CPAPKE.Dec 和 Kyber.CPAPKE.Enc |
| 密文验证与密钥派生 | 和备用密钥 | 和备用密钥 |
所有参数集大小
公钥大小:
Aigis-enc
kyber
私钥大小:
Aigis-enc
kyber
密文格式
Aigis-enc
kyber